
diff options
| author | Priyansh <[email protected]> | 2021-07-05 19:44:27 +0530 |
|---|---|---|
| committer | Priyansh <[email protected]> | 2021-07-05 19:44:27 +0530 |
| commit | c111b8dad4461e4366bf245254bfce20a5976edf (patch) | |
| tree | 711791d4b58274cef9420e1e2a565f49494b8c5d | |
| parent | cd0508b3beb5ada72b33e3fe8dcf88105d5131c3 (diff) | |
| download | luciferreeves.github.io-c111b8dad4461e4366bf245254bfce20a5976edf.tar.xz luciferreeves.github.io-c111b8dad4461e4366bf245254bfce20a5976edf.zip | |
Migrated Posts /w some changes
4 files changed, 362 insertions, 29 deletions
diff --git a/_posts/2021-01-16-big-o-notation-explained-as-easily-as-possible.md b/_posts/2021-01-16-big-o-notation-explained-as-easily-as-possible.md new file mode 100644 index 0000000..78a8840 --- /dev/null +++ b/_posts/2021-01-16-big-o-notation-explained-as-easily-as-possible.md @@ -0,0 +1,72 @@ +--- +layout: post +title: "Big O Notation - explained as easily as possible" +date: 2021-01-16 00:00:00 +0530 +author: Priyansh +tags: data-structures algorithms computer-science +usemathjax: true +--- +{% include math.html %} + +Data Structures and Algorithms is about solving problems efficiently. A bad programmer solves their problems inefficiently and a really bad programmer doesn't even know why their solution is inefficient. So, the question is, *How do you rank an algorithm's efficiency?* + +> If you want to learn the math involved with the Big O, read [Analysing Algorithms: Worst Case Running Time](../2021-01-22/analysing-algorithms-worst-case-running-time). + +The simple answer to that question is the **Big O Notation**. How does that work? Let me explain! + +Say you wrote a function which goes through every number in a list and adds it to a *total_sum* variable. + +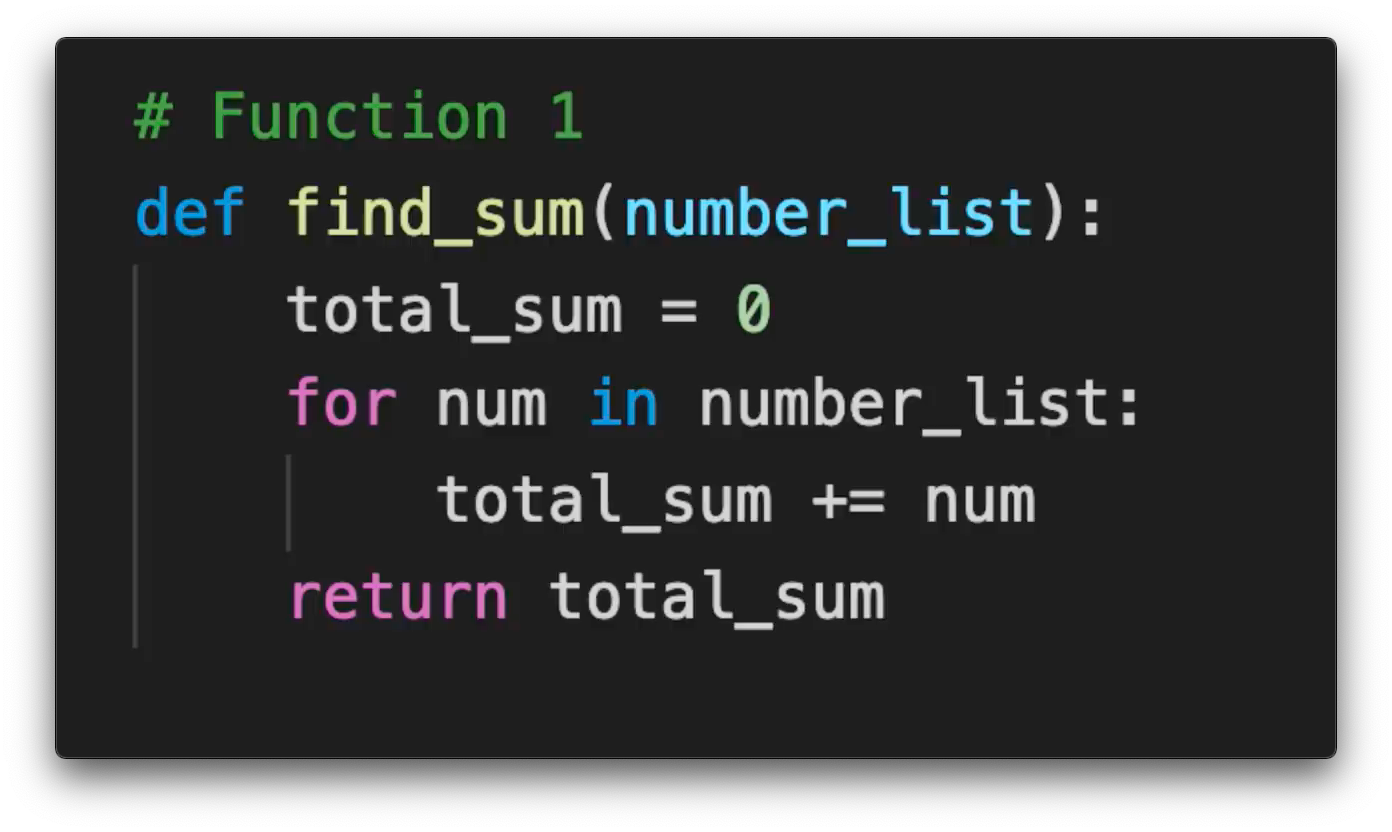 + +If you consider "addition" to be 1 operation then running this function on a list of 10 numbers will cost 10 operations, running it on a list of 20 numbers costs 20 operations and similarly running it on a list of n numbers costs the *length of list* (n) operations. + + + +Now let's assume you wrote another function that would return the first number in a list. + +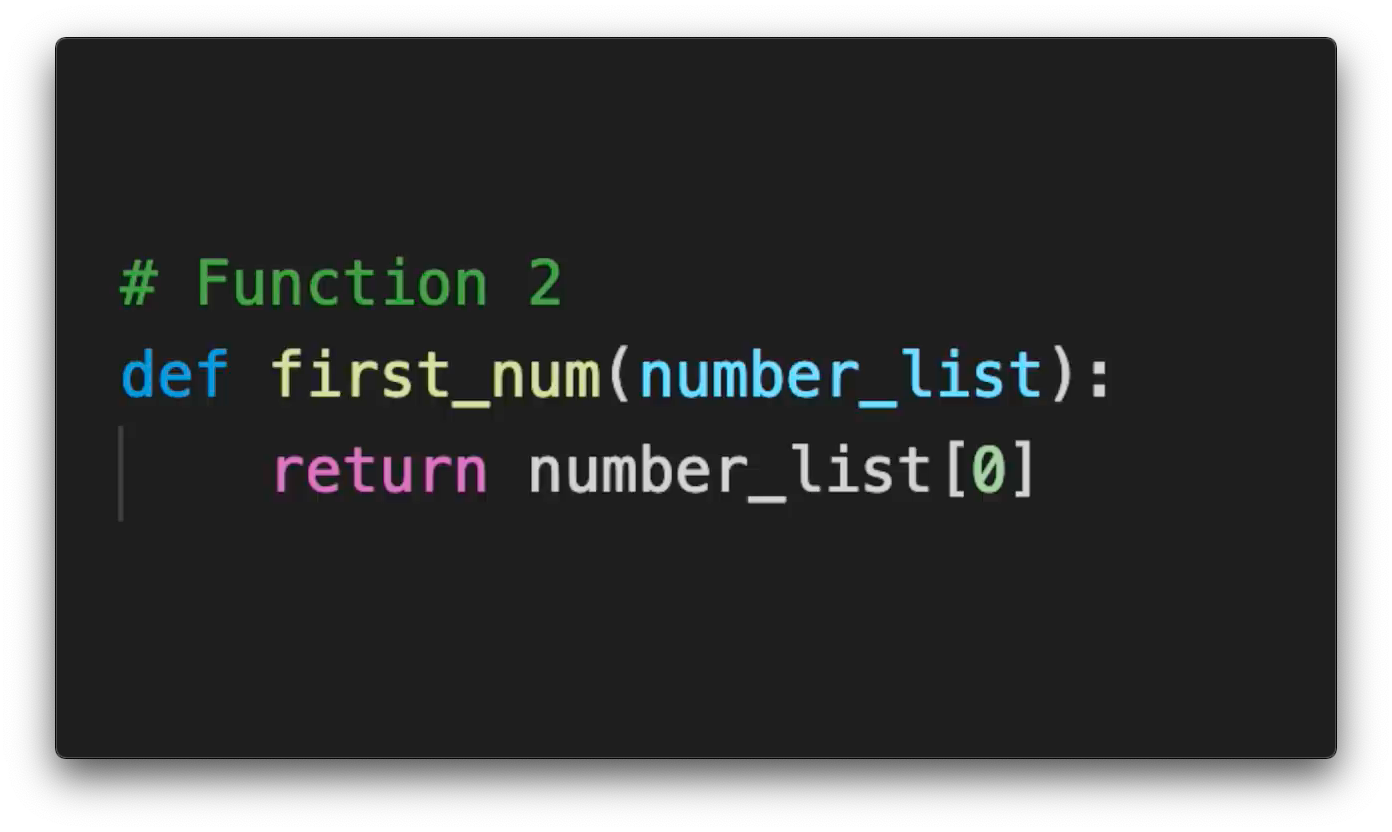 + +Now, no matter how large this list is, this function will never cost more than one operation. Fairly, these two algorithms have different **time complexity** or *relationship between growth of input size and growth of operations executed*. We communicate these time complexities using ***Big O Notation***. + +> Big O Notation is a mathematical notation used to classify algorithms according to how their run time or space requirements grow as the input size grows. + +Referring to the complexities as *'**n**'*, common complexities (ranked from good to bad) are: + +- Constant - **O(1)** +- Logarithmic **O(log n)** +- Linear - **O(n)** +- n log n - **O(n log n)** +- Quadratic - **O(n²)** +- Exponential - **O(2ⁿ)** +- Factorial - **O(n!)** + +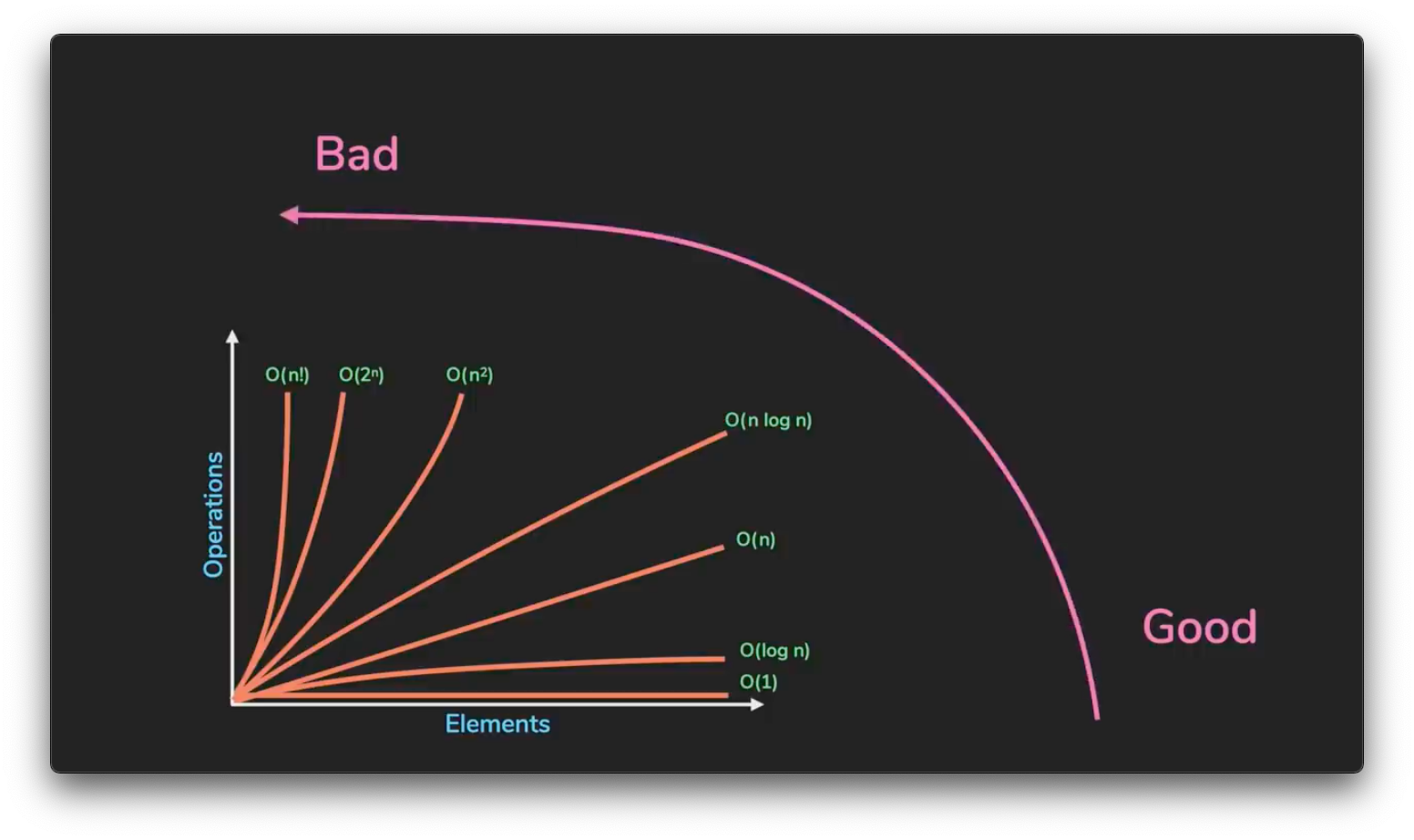 + +Our first algorithm runs in *O(n)*, meaning its operations grew in a linear relationship with the input size - in this case, the amount of numbers in the list. Our second algorithm is not dependent on the input size at all - so it runs in constant time. +Let's take a look at how many operations a program has to execute in function with an input size of *n = 5 vs n = 50*. + +| | n = 5 | n = 50 | +|----------------|-------|------------------| +| **O(1)** | 1 | 1 | +| **O(log n)** | 4 | 6 | +| **O(n)** | 5 | 50 | +| **O(n log n)** | 20 | 300 | +| **O(n²)** | 25 | 2500 | +| **O(2ⁿ)** | 32 | 1125899906842624 | +| **O(n!)** | 120 | 3.0414093e+64 | + +It might not matter when the input is small, but this gap gets very dramatic as the input size increases. + + + +If n were 10000, a function that runs in *log(n)* would only take 14 operations and a function that runs in *n!* would set your computer on fire! + +For Big O Notation, we *drop constants* so *O(10.n)* and *O(n/10)* are both equivalent to *O(n)* because the graph is still linear. + +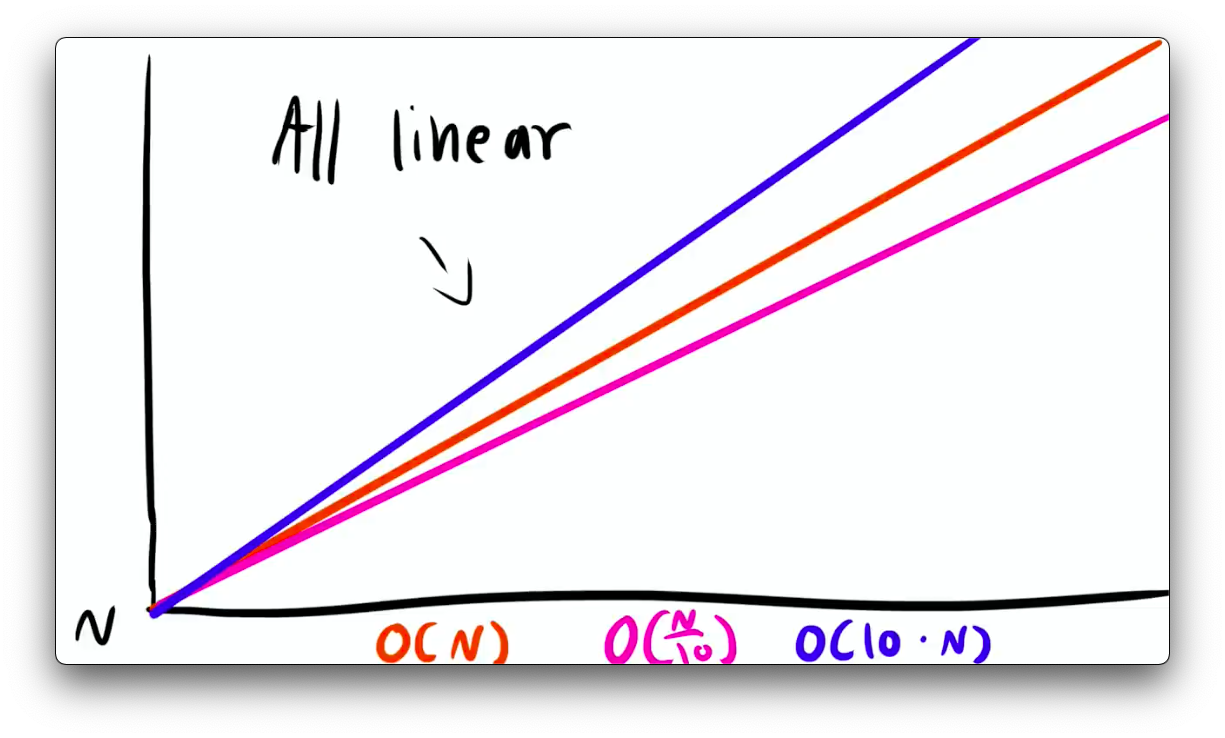 + +Big O Notation is also used for **space complexity**, which works the same way - *how much space an algorithm uses as n grows* or *relationship between growth of input size and growth of space needed*. + +So, yeah! This has been the simplest possible explanation of the Big O Notation from my side and I hope you enjoyed reading this. If you found this information helpful, share it with your friends on different social media platforms. It really motivates me to write more. And If you REALLY liked the article, consider [buying me a coffee](https://ko-fi.com/luciferreeves) 😊 + +***Happy Programming!*** diff --git a/_posts/2021-01-22-analysing-algorithms-worst-case-running-time.md b/_posts/2021-01-22-analysing-algorithms-worst-case-running-time.md new file mode 100644 index 0000000..b1a69be --- /dev/null +++ b/_posts/2021-01-22-analysing-algorithms-worst-case-running-time.md @@ -0,0 +1,197 @@ +--- +layout: post +title: "Analysing Algorithms: Worst Case Running Time" +date: 2021-01-22 00:00:00 +0530 +author: Priyansh +tags: data-structures algorithms computer-science +usemathjax: true +--- +{% include math.html %} + +In my [last article](../2021-01-16/big-o-notation-explained-as-easily-as-possible), I tried to give a beginner friendly explanation of the ***Big O Notation*** but we skipped out on a lot of stuff. So I am going to talk about **analyzing algorithms** today, specifically the ***worst-case running time of algorithms***, which indeed is the ***Big O***, while still keeping this article beginner friendly only. As we progress in the series, I would gradually start talking on higher levels and will try to discuss about most important factors of these concepts. + +One thing to keep in mind is that Big O is just a notation and can be used to denote a variety of things but we will stick to the worst case running time only in this article. + + +### Worst-Case Running Time is tricky... + +As you already know, we are focusing on the worst-case running times but even talking about worst-case running time can be tricky if we are trying to be precise. We have to identify the *worst case input* in detail, which can be counter-intuitive and then work through a lot of different cases. Also, if you followed the [last article](../2021-01-16/big-o-notation-explained-as-easily-as-possible), we were counting the single operations or steps of different algorithms, which might get annoying as the algorithm becomes more and more complex. + + + +As we have discussed earlier too, that we drop the constants for the Big O notation (again, read the [last article](../2021-01-16/big-o-notation-explained-as-easily-as-possible)) — so, if an algorithm has a running time of ***2n² + 23*** operations and another algorithm has a running time of ***2n² + 27*** operations (both for an input of size n), we wouldn't really care about the 23 or 27 — we would say that essentially they have the same running time. + + + +### Dropped Constants? Why? + +If you analyze the math correctly, you'll notice a big flaw with what I just said about dropping the constants. According to the statement I made above, an algorithm with a running time of 10000n and another algorithm with a running time of n, would have the same running time, according to the Big O notation, i.e. *O(n)*. But, any first grader can argue that, a function which takes 10000n time units to run is way slower than a function which takes n time units to run. + +The fact that the functions are both O(n) doesn't change the fact that they don't run in the same amount of time, since that's not what Big O notation is designed for. Big O notation only describes the growth rate of algorithms in terms of mathematical function, rather than the actual running time of algorithms on some machine. + +Mathematically speaking, let us assume two functions `f(x)` and `g(x)` be positive for x sufficiently large. We say that `f(x)` and `g(x)` grow at the same rate as x tends to infinity, if + +$$ \displaystyle \lim_{x \to \infty} \frac{f(x)}{g(x)} = M \neq 0 \text{ (M is a finite non-zero number)}. \ $$ + +Now, let `f(x) = x²` and `g(x) = x²/2` then while `limit(x ⟶ ∞)f(x)/g(x)` is equal to 2. Therefore, x² and x²/2 have the same growth rate, and hence we can say **O(x²)** is equal to **O(x²/2)**. + + + +### Wait, but how do I calculate that running time? + +Yes I get you mate — you're tired of listening that running of this algorithm of this much and running time of that algorithm is that much, but you never got to know, how the heck they are even being calculated! So, in order to make you understand and at the same time keeping this very simple, we will go back to counting. We will count time units for every operation performed and we will stick to 3 small rules: + +- '**simple**' operations (*such as **adding** two numbers, **multiplying** them or executing an **if** or **for** statement*) take *1 time unit* + +- loops count as often they run (*for example, if you have a loop that executes a simple operation 100 times, that would count as 100 time units*) + +- memory access is free, i.e. *0 time units* (*example: reading a part of input or writing something to memory cell*) + + + +In order to understand the above steps, let's look at some examples. Look at the lines of code below and try to guess how many time units would this code chunk takes to execute: + +```python +a = 1 +b = 2 * a +``` + +So, the answer here is that the machine is going to take just a single time unit (one time unit) to execute these two lines of code because line `a = 1` is just a memory access and we get memory access for free. The second line performs a simple operation, which takes 1 time unit. + + + +Now, let's try a little more challenging example. It's not really challenging but a little more difficult than the first one. Look at the code below and try to find the number of time units and note that the comparison `while s > 0` counts as a simple operation: + +```python +s = 5 +while s > 0: + s = s -1 +``` + +If your answer is 11 time units then you're right! The first line `s = 5` is free as it is a memory access. Then the second line is executed 6 times as **s** starts at 5 then it becomes 4, 3, 2, 1 and 0 which takes 6 time units. Finally, the last line is executed 5 times which takes 5 time units – bringing the total to 11 time units. + + + +### Running time vs Structure + +So, as you can see, exactly counting the number of time units even though we have a very simple model of just 3 rules and a code that doesn't even have a variable input is already quite tedious. That's why we introduce some additional simplifications (*Spoiler: Approaching the Big O!*) that gives us a little bit levy here so that we don't have to through this exact counting process but still learn about the algorithm. + + + +Now, you already know that the ***running time of an algorithm varies according to the size of the input (n)*** but the ***running time can also change with the content or structure of the input***. Let's explain this with an example. Our algorithm takes a string `s[0] to s[n-1]` i.e., a string of length n and it counts the number of times the character 'a' appears in the string by looping over the string and if it finds the character 'a', it would increase the counter. As discussed earlier, we are going to take the `for character in s:` line as a simple operation (takes *1 time unit* each time it is executed) and we are also going to consider the comparison `if character == 'a'` as a simple operation. Now, for the last time, I want you to count the number of time units taken by the code to execute. (*Hint: you need to take two variables into account: **n - length of the string** and the **a - denotes the number of times that the character 'a' actually appears in the string s**.*) + +``` +INPUT: String s[0]...s[n-1] // string of length n +``` + +```python +count = 0 +for character in s: + if character == 'a': + count = count + 1 +``` + +There's actually two correct answers here depending upon how you think about it. Both answers have **2n + 1a** in common and depending upon how you count the `for character in s:` line, the answer would be either **2n + 1a + 0** or **2n + 1a + 1**. So, let's discuss, why? The first line `count = 0` obviously takes 0 time units. The second line either takes **n time units** if you assume that the for loop goes exactly through each character of the string and then stops immediately or it takes **n + 1 time units** if you assume that it executed like a regular for or while loop. This again shows that it can be very annoying to do exact time counting. The next step though, is always executed **n times**. And finally, the counter is always increased when the algorithm encounters an 'a', so that is executed exactly **a times**. If you sum up, you get either **2n + 1a + 0** or **2n + 1a + 1** as your answer. + + + +Let's assume for now, that the running time of the above algorithm is **2n + 1a + 1**. As you've noticed, even for this simple algorithm, the running time depends on both the size of the inputs and the structure of the input, which in this case, is the number of times the letter 'a' occurs. This is of course very problematic because on the one hand when we get more complicated algorithms the formula (*here: 2n + 1a + 1*) is going get very complicated and secondly, we don't even know what kinds of strings the algorithm will encounter, so we cannot get rid of this variable **a** without making any assumptions. + + + +Based upon all this information, we can take 3 kinds of views with regard to our running time: + +1. Optimistic View - **Best Case Scenario** - *when we will not encounter any number of the letter 'a' in our input, i.e. the running time becomes **2n + 1**.* + +2. Average View - **Average Case Scenario** - *Gosh, how do we even define an average input?* + +3. Pessimistic View - **Worst Case Scenario** - *when all the characters of the string s are 'a' - that means we have n number of a's (or a = n) i.e. the running time becomes 2n + 1n + 1 or **3n + 1**.* + + + +So, which one of the three are we going to choose? Best case running time is often rather trivial or meaningless. For example, if we use best case running time for our algorithm that counts the number of a's, it would only be valid for strings that contain no 'a' at all – we can't take this. The average case view, could be very interesting view and practice because we run the algorithm a couple of times, we might not care about how much that algorithm runs in a single run but over many inputs. But, as I told you earlier, its hard to define what an average input looks like so as interesting the average case looks like, it is not suitable here. We will **always assume that the algorithm receives the input that makes it run as long as possible** because it offers *guarantees* — by taking a worst-case view, we know that our algorithm would not run longer than what the worst-case analysis suggests, no matter what happens! + + + +### Understanding Big O + +Let's consider two different algorithms, Algorithm A with a running time of **3n² -n + 10** and Algorithm B with running time of **2ⁿ - 50n + 256**. So, when you compare both of these algorithms, you can easily overlook the numbers 10 and 256 because those are just constants. Also we don't really care about the -n or -50n because we just look at the growth of 2ⁿ vs 3n². And even 3 is not relevant here in 3n² because even if we had 5n² or 6n² or even 100n², 2ⁿ would still grow much faster (*Why? Get a basic mathematics book and find out!*). + + + +So, what did we just do when we determined that the running time of Algorithm B grows much faster than the running time of Algorithm A? Well, first of all, we said that there was some value of n (*some value for the size of the input*) where the Algorithm B's running time function is always larger than Algorithm A's running time function. So, considering the running time of Algorithm A is some function `f(n)` and the running time of Algorithm B is some function `g(n)` and if `g(n)` grows faster than `f(n)` then there must be some value of n for which `g(n)` is larger than `f(n)` and for any value larger than that, the same should also be true (***g(n) > f(n)***) — Let's call that value `n'`. Based on all of this, we can conclude that: + +1. There is some number `n'`, so that `g(n') ≥ f(n')` + +2. For any `n'' > n'`, we have `g(n'') ≥ f(n'')` + + + +Now, I also said that we do not want to care about constants — so we do not want to care about if `f(n)` starts with 3n² or 5n² — we would just say that the function `f(n)` basically grows depending upon n². So, in order to do that we need another number, a constant `c` to be multiplied to `g(n)` that would allow to scale the function `g(n)` – basically speaking, if we can multiply the function `g(n)` with some number so that it outgrows `f(n)` then we would still be satisfied. Then we would say that `g(n)` grows at least as fast as`f(n)`. So the first statement can be restated as: + + + +*There is some number `n'c`, so that `c.g(n') ≥ f(n')`* + + + +It can also be said that, `f(n)` is contained in Big O of `g(n)` and is represented as `f(n) ∈ O(g(n))`. So, **Big O means that `g(n)` is a function that grows at least as fast as `f(n)`**. + + + +### Recognizing Bounds using Big O + +Big O notation is very useful because we can use it to concentrate just on the fastest growing part of a function and even without all the involved constants. Now let's focus on some example, so that you learn to recognize these bounds correctly. + +1. 3n + 1 ∈ O(n) — *obvious, meh* 🤷🏻♂️ + +2. 18n² - 50 ∈ O(n²) — *meh again* 🤷🏻♂️ + +3. 2ⁿ + 30n⁶ + 123 ∈ O(2ⁿ) — *as 2ⁿ grows faster than n⁶* + +4. 2ⁿ.n² + 30n⁶ + 123 ∈ O(2ⁿ.n²) — *2ⁿ.n² being the fastest growing function* + + + +> **FUN TRIVIA**: Big O notation is also sometimes called the **Landau Notation**, named after the German mathematician, ***Edmund Landau*** — he didn't actually invent the notation. It was done by another German mathematician called ***Paul Bachman***, but he popularized it in the 20th century. In a way, this is quite ironic because Edmund Landau was actually known as one of the most exact and pedantic mathematicians. His goal was uncompromisingly rigorous. Even in his lectures, he used to have an assistant who was instructed to interrupt him if he even omitted the slightest detail. It is interesting that he introduced a notation that omits all the details. + + + +### Running time using Big O Notation + +So, now that you've learnt the basics about Big O and Worst Case Analysis, let's take a look at another example and try to calculate the running time. But this time, we will use the Big O! So, this time we are using a similar example as earlier but instead of counting number of times the letter 'a' appears in the string, we are counting the number of times the sequence 'ab' appears in the string. + +``` +INPUT: String s[0]...s[n-1] // string of length n +``` + +```python +count = 0 +for i in range(n - 1): + if s[i] == 'a': + if s[i+1] == 'b': + count = count + 1 +``` + +As you remember, this was painful to do as we had to manually count everything. But now that we have the Big O notation available, our task is much easier because we can just make two observations and will be able to state the running time. So the first observation you make is that the algorithm will actually go through the string one by one, and since it always looks at a single character and the next character, **the algorithm will look at each character in the string at most twice**. And the second thing to notice is that each time the algorithm does consider a character, it will perform a constant number of operations — so if it finds an 'a' it would either do one or two operations and if doesn't find an 'a', it would do zero operations — and this is an advantage, because we can ignore the constants while using the Big O notation. So overall, this means if you have an input of length n, the algorithm will perform a number of steps that is some constant times n plus some constant for all the rest of the operations, i.e., **c₁.n + c₂** which indeed ∈ O(n). + + + +Let's consider one more example and try to find out the running time of this code: + +```python +result = 0 +for i in range (0, n): + for j in range(i, n): + result = result + j +``` + +And the answer for this is O(n²). So let's discuss, why! The first line is a memory access, so its free. As discussed earlier, second line is going to be executed either n or n + 1 times – that doesn't make any difference as we are using the Big O now, so the second line is executed *n times*. Now, we need to find out how often the inner loop is executed. So, the first time, it's actually executed n times, then the next time it is going to be executed n-1 times and so on and so forth because as the value of **i** increases the inner loop is executed less and less times. So, the total times the inner loop is executed is `n + (n-1) + (n-2) + ... + 2 + 1` which is equal to \\( \frac{n^2 + n}{2} \\) . And again, we can ignore the 2 in the denominator making it equal to \\( n^2 + n \\). So the complete total is n² + 2n ∈ O(n²). + + + +### Time to take a leave now... + +That was a long article — I hope you didn't get bored reading that. Well, once again, this is point where I beg you for following the blog. If you found this information helpful, share it with your friends on different social media platforms. It really motivates me to write more. And If you REALLY liked the article, consider [buying me a coffee](https://ko-fi.com/luciferreeves) 😊 + +***Happy Programming!*** diff --git a/_posts/2021-02-02-most-beautiful-question-of-computer-science-math.md b/_posts/2021-02-02-most-beautiful-question-of-computer-science-math.md new file mode 100644 index 0000000..3d6a558 --- /dev/null +++ b/_posts/2021-02-02-most-beautiful-question-of-computer-science-math.md @@ -0,0 +1,93 @@ +--- +layout: post +title: "Most Beautiful Question of Computer Science (+Math)" +date: 2021-02-02 00:00:00 +0530 +author: Priyansh +tags: data-structures algorithms computer-science +usemathjax: true +--- +{% include math.html %} + +Most beautiful question? Is that a click bait? Well, of course it is — beauty is present in the mind of the perceiver and not in the outside world. (*Damn it! That's some life changing philosophy!*) + +So, coming to the question again, today I am going to introduce you to one of my favourite and as I said most beautiful beginner friendly questions that you will encounter in Computer Science (and also Mathematics). You guys, ready? Here it goes: + + + +Now I really like this question because it sounds so absurd in the beginning, right? Its almost as if I am saying that I have 4 mangoes and I give 2 of them to John. Now calculate the mass of the sun! Anyways, you can stop reading here and try to solve it, but let go through the explanation of the solution for this question. + +So, the basic idea is to randomly draw points in a 1:1 square (a square with a side of unit length) or a 1:1 grid. Then, you can call the `random()` function twice, so you get two numbers and you can use one for the x-axis and one for the y-axis (*example: x = 0.2 and y = 0.6*) and you can generate a whole lot of these. + + + +So now, I am going to give you a hint. I am gonna draw something and you'll probably know how to do this. + + +Got it? No? Let's elaborate a little more then! + +As you can see, the goal here is count all the points in the circle and count all the points in the square. The ratio between these numbers would be pretty close to the ratio between the total area of the circle and the area of the square. + + + +So, how do you know if a point is in the circle or not? Well, it is very simple. You just take the distance between point and the origin and if it is smaller than 1, it is inside the circle. So, what would be the distance of a point at co-ordinates `(x, y)` from the origin? The distance is: + +$$ distance = \sqrt{x^2 + y^2} $$ + +If the above distance is < 1 than it is inside the circle and if it is > 1 than it is outside the circle but still inside the square. So, now it's basic algebra from here. As we all know that the area of a circle is \\( \pi r^2 \\) (considering the radius of the circle is *r*) — oh, you didn't knew? Hmph, fucking idiot! And then, in this case, the area of the square will be \\( (2 \cdot r)^2 \\). And this ratio would be equal to the ratio of number to points in the circle and the total number of points. + +$$ \frac{\pi r^2}{(2\cdot r)^2} = \frac{\mathrm{number\:of\:points\:in\:the\:circle}}{\mathrm{total\:number\:of\:points}} $$ + +Now we need value of \\( \pi \\), so that would be pretty easy as we know, \\( r = 1 \\) here. Therefore: + +$$ \pi = \frac{4 \cdot \mathrm{number\:of\:points\:in\:the\:circle}}{\mathrm{total\:number\:of\:points}} $$ + +So, yeah! That's pretty much it. Coding it should be pretty easy, so I am not going to go over that. + +Wait! I changed my mind. I think I am going to show the code as it can explain things a *little* bit better. So, I am going to define a function called `estimate_pi` and it takes an input of `n` — n being how many points you want to put in — the more points the more accurate the result is. And then I will initialise the number of points in the circle and total number of points - both to zero. Mind that the code shown here is in python but you can easily translate it to any other language of your choice. + + +```python +def estimate_pi(n): + num_point_circle = 0 + num_point_total = 0 +``` + +So, now we just want to keep looping and keep adding these points. So we loop over n times and on every iteration, we generate two random numbers x and y — and then we will calculate the \\( distance = \sqrt{x^2 + y^2} \\) but we can actually drop the square root because what we care about is if the distance is smaller than 1, and if you square root something smaller than 1, it would be smaller than 1 and if you square root something bigger than 1, it is going to be bigger than 1. So if the distance is smaller than 1, then it is inside the circle and we will increase `num_point_circle` by 1 and we would also increase `num_point_total` by 1, no matter what. + +```python +def estimate_pi(n): + num_point_circle = 0 + num_point_total = 0 + +for _ in range(n): + x = random.uniform(0,1) + y = random.uniform(0,1) + distance = x**2 + y**2 + if distance <= 1: + num_point_circle += 1 + num_point_total += 1 +``` + +Finally you can return `return 4*num_point_circle/num_point_total` as your result and don't forget to import the `random` library. So the whole code looks like: + +```python +import random + +def estimate_pi(n): + num_point_circle = 0 + num_point_total = 0 + for _ in range(n): + x = random.uniform(0,1) + y = random.uniform(0,1) + distance = x**2 + y**2 + if distance <= 1: + num_point_circle += 1 + num_point_total += 1 + + return 4*num_point_circle/num_point_total +``` + +Here, you can see that I have run the `estimate_pi` function a few times with different sizes of n and as we use more and more data points, we get a value closer to actual pi. Although, it would be very hard to determine the exact value of pi. If you want to try the code for yourself, you can view my repl here: [https://repl.it/@luciferreeves/SpottedTechnicalReality](https://repl.it/@luciferreeves/SpottedTechnicalReality) . + + +Well, that's it for this article guys! If you found this information helpful, share it with your friends on different social media platforms. It really motivates me to write more. And If you REALLY liked the article, consider [buying me a coffee](https://ko-fi.com/luciferreeves) 😊 diff --git a/_posts/2021-07-05-welcome-to-jekyll.markdown b/_posts/2021-07-05-welcome-to-jekyll.markdown deleted file mode 100644 index 07d701e..0000000 --- a/_posts/2021-07-05-welcome-to-jekyll.markdown +++ /dev/null @@ -1,29 +0,0 @@ ---- -layout: post -title: "Welcome to Jekyll!" -date: 2021-07-05 17:32:20 +0530 -categories: jekyll update ---- -You’ll find this post in your `_posts` directory. Go ahead and edit it and re-build the site to see your changes. You can rebuild the site in many different ways, but the most common way is to run `jekyll serve`, which launches a web server and auto-regenerates your site when a file is updated. - -Jekyll requires blog post files to be named according to the following format: - -`YEAR-MONTH-DAY-title.MARKUP` - -Where `YEAR` is a four-digit number, `MONTH` and `DAY` are both two-digit numbers, and `MARKUP` is the file extension representing the format used in the file. After that, include the necessary front matter. Take a look at the source for this post to get an idea about how it works. - -Jekyll also offers powerful support for code snippets: - -{% highlight ruby %} -def print_hi(name) - puts "Hi, #{name}" -end -print_hi('Tom') -#=> prints 'Hi, Tom' to STDOUT. -{% endhighlight %} - -Check out the [Jekyll docs][jekyll-docs] for more info on how to get the most out of Jekyll. File all bugs/feature requests at [Jekyll’s GitHub repo][jekyll-gh]. If you have questions, you can ask them on [Jekyll Talk][jekyll-talk]. - -[jekyll-docs]: https://jekyllrb.com/docs/home -[jekyll-gh]: https://github.com/jekyll/jekyll -[jekyll-talk]: https://talk.jekyllrb.com/ |